
AutoGen Studio: A No-Code Developer Tool for Building and Debugging Multi-Agent Systems
- Victor Dibia ,
- Jingya Chen ,
- Gagan Bansal ,
- Suff Syed ,
- Adam Fourney ,
- Erkang (Eric) Zhu ,
- Chi Wang ,
- Saleema Amershi
Preprint
Multi-agent systems, where multiple agents (generative AI models + tools) collaborate, are emerging as an effective pattern for solving long-running, complex tasks in numerous domains. However, specifying their parameters (such as models, tools, and orchestration mechanisms etc,.) and debugging them remains challenging for most developers. To address this challenge, we present AUTOGEN STUDIO, a no-code developer tool for rapidly prototyping, debugging, and evaluating multi-agent workflows built upon the AUTOGEN framework. AUTOGEN STUDIO offers a web interface and a Python API for representing LLM-enabled agents using a declarative (JSON-based) specification. It provides an intuitive drag-and-drop UI for agent workflow specification, interactive evaluation and debugging of workflows, and a gallery of reusable agent components. We highlight four design principles for no-code multi-agent developer tools and contribute an open-source implementation on GitHub (opens in new tab).
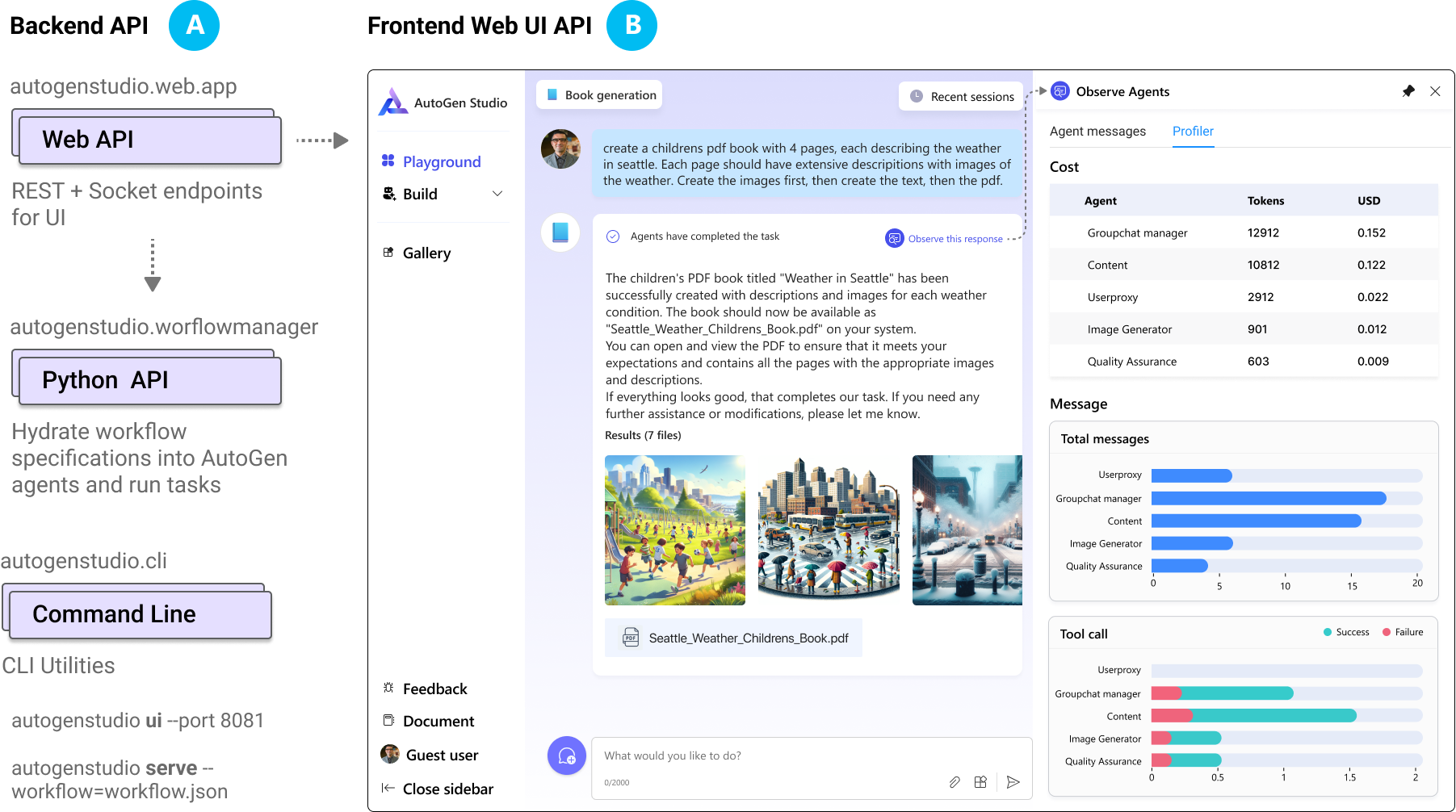
AUTOGEN STUDIO provides a backend api (web, python, cli) and a UI which implements a playground (shown), build and gallery view. In the playground view, users can run tasks in a session based on a workflow. Users can also observe actions taken by agents, reviewing agent messages and metrics based on a profiler module.
 GitHub
GitHub
What’s new in AutoGen?
Presented by Chi Wang at Microsoft Research Forum, Episode 2
Chi Wang discussed the latest updates on AutoGen – the multi-agent framework for next generation AI applications. This includes milestones achieved, community feedback, new exciting features, and ongoing research and challenges.
Transcript
What’s new in AutoGen?
CHI WANG: Hi, everyone. My name is Chi. I’m from Microsoft Research AI Frontiers. I’m excited to share with you the latest news about AutoGen. AutoGen was motivated by two big questions: what are the future AI applications like, and how do we empower every developer to build them? Last year, I worked with my colleagues and collaborators from Penn State University and University of Washington on a new multi-agent framework.
We have been building AutoGen as a programing framework for agent AI, like PyTorch for deep learning. We developed AutoGen inside an open-source project, FLAML, and in last October, we moved it to a standalone repo on GitHub. Since then, we’ve got new feedback from users every day, everywhere. Users have shown really high recognition of the power of AutoGen, and they have deep understanding of the values in different dimensions like flexibility, modularity, simplicity.
Let’s check one example use case.
[Beginning of pre-recorded testimonial.]
Sam Khalil, VP, Data Insights & FounData, Novo Nordisk: In our data science department, AutoGen is helping us develop a production ready multi-agent framework.
Rasmus Sten Andersen, AI engineer lead, Novo Nordisk: Our first target is to reduce the barriers to technical data analytics and to enable our broader community to derive insights.
Georgios Ilias Kavousanos, data engineer, AI Labs, Novo Nordisk: We are also extending AutoGen with the strict requirements from our industry given the sensitive nature of our data.
[End of pre-recorded testimonial.]
WANG: That is one example use case from the pharmacy vertical. We have seen big enterprise customers’ interest like this from pretty much every industry vertical. AutoGen is used or contributed [to] by companies, organizations, universities from A to Z, all over the world. We have seen hundreds of example applications, and some organizations use AutoGen as a backbone to build their own agent platform, and others use AutoGen for diverse scenarios, including research and investment to novel and creative applications of multiple agents. AutoGen has a large community—very active—of developers, researchers, AI practitioners. They are so active and passionate. I’m so amazed by that, and I appreciate all the recognition that was received by AutoGen in such a short amount of time. For example, we have been selected, our paper is selected by TheSequence as one of the top favorite AI papers in 2023. To quickly share our latest news, last Friday, our initial multi-agent experiment on the challenging GAIA benchmark turned out to achieve the No. 1 accuracy in the leaderboard in all the three levels. That shows the power of AutoGen in solving complex tasks and the bigger potential.
This is one example of our effort in answering a few open hard questions, such as how to design an optimal multi-agent workflow. AutoGen is under active research and development and is evolving at a very fast pace. Here are examples of our exciting new features or ongoing research. First, for evaluation, we are making agent-based evaluation tools or benchmarking tools. Second, we are making rapid progress in further improving the interface to make it even easier to build agent applications. Third, the learning capability allows agents to remember teachings from users or other agents long term and improve over time. And fourth, AutoGen is integrated with new technologies like OpenAI assistant and multimodality. Please check our blog post from the website to understand more details.
I appreciate the huge amount of support from everyone in the community, and we need more help in solving all the challenging problems. You’re all welcome to join the community and define the future of AI agents together.
Thank you very much.
AutoGen Update: Complex Tasks and Agents
Presented by Adam Fourney at Microsoft Research Forum, Episode 3
Adam Fourney discusses the effectiveness of using multiple agents, working together, to complete complex multi-step tasks. He will showcase their capability to outperform previous single-agent solutions on benchmarks like GAIA, utilizing customizable arrangements of agents that collaborate, reason, and utilize tools to achieve complex outcomes.
Transcript
AutoGen Update: Complex Tasks and Agents
ADAM FOURNEY: Hello, my name is Adam Fourney, and today, I’ll be presenting our work on completing complex tasks with agents. And though I’m presenting, I’m sharing the contributions of many individuals as listed below. All right, so let’s just dive in.
So in this presentation, I’ll share our goal, which is to reliably accomplish long-running complex tasks using large foundational models. I’ll explain the bet that we’re taking on using multi-agent workflows as the platform or the vehicle to get us there, and I’ll share a little bit about our progress in using a four-agent workflow to achieve state-of-the-art performance on a recent benchmark.
So what exactly is a complex task? Well, if we take a look at the following example from the GAIA benchmark for General AI Assistants, it reads, “How many nonindigenous crocodiles were found in Florida from the years 2000 through 2020?” Well, to solve this task, we might begin by performing a search and discovering that the U.S. Geological Survey maintains an online database for nonindigenous aquatic species. If we access that resource, we can form an appropriate query, and we’ll get back results for two separate species. If we open the collection reports for each of those species, we’ll find that in one instance, five crocodiles were encountered, and in the other, just a single crocodile was encountered, giving a total of six separate encounters during those years. So this is an example of a complex task, and it has certain characteristics of tasks of this nature, which is that it benefits strongly from planning, acting, observing, and reflecting over multiple steps, where those steps are doing more than just generating tokens. Maybe they’re executing code. Maybe they’re using tools or interacting with the environment. And the observations they’re doing … they’re adding information that was previously unavailable. So these are the types of tasks that we’re interested in here. And as I mentioned before, we’re betting on using multi-agent workflows as the vehicle to get us there.
So why multi-agents? Well, first of all, the whole setup feels very agentic from, sort of, a first-principles point of view. The agents are reasoning, they’re acting, and then they’re observing the outcomes of their actions. So this is very natural. But more generally, agents are a very, very powerful abstraction over things like task decomposition, specialization, tool use, etc. Really, you think about which roles you need on your team, and you put together your team of agents, and you get them to talk to one another, and then you start making progress on your task. So to do all this, to build all this, we are producing a platform called AutoGen (opens in new tab), which is open source and available on GitHub. And I encourage you to check this out at the link below.
All right, so now let’s talk about the progress we’ve been making using this approach. So if you recall that question about crocodiles from the beginning, that’s from the GAIA benchmark for General AI Assistants. And we put together four agents to work on these types of problems. It consists of a general assistant, a computer terminal that can run code or execute programs, a web server that can browse the internet, and an orchestrator to, sort of, organize and oversee their work. Now with that team of four agents, we were actually able to, in March, achieve the top results on the GAIA leaderboard for that benchmark by about 8 points. But what’s perhaps more exciting to us is that we are able to more than double the performance on the hardest set of questions, the Level 3 questions, which the authors of that work describe as questions for a perfect general assistant, requiring to take arbitrarily long sequences of actions, use any number of tools, and to access the world in general. So this is all very exciting, and I want to share a little bit more about what those agents are actually doing.
So this is the loop or the plan that they are following. So it begins with the question or the prompt, and then we produce a ledger, which is like a working memory that consists of given or verified facts; facts that we need to look up, for example, on the internet; facts that we need to derive, perhaps through computation; and educated guesses. Now these educated guesses turn out to be really important because they give the language models space to speculate in a constrained environment without some of the downstream negative effects of hallucination. So once we have that ledger, we assign the tasks to the independent agents, and then we go into this inner loop, where we ask first, are we done? If not, well, are we still making progress? As long as we’re making progress, we’ll go ahead and we’ll delegate the next step to the next agent. But if we’re not making progress, we’ll note that down. We might still delegate one other step, but if that stall occurs for three rounds, then we will actually go back, update the ledger, come up with a new set of assignments for the agents, and then start over.
All right, so this is the configuration that’s been working well for us, and it’s all I have time to share with you today. But I mentioned our goal, our bet, and our progress, and I want to conclude by sharing our plans for the future. So already we’re starting to tackle increasingly more complex benchmarks and real-world scenarios with this configuration. And we’re really excited about opportunities to introduce new agents that, for example, learn and self-improve with experience; that understand images and screenshots a little better for maybe more effective web surfing or use of interfaces; and that are maybe a bit more systematic about exploring that solution space. So rather than just updating that ledger and then restarting when they get stuck, they can be a bit more pragmatic about the strategies that they’re employing.
All right, well, thank you for your attention, and thank you for attending the Microsoft Research Forum, and we look forward to you joining us next time.
 Microsoft research copilot experience
What updates did Adam Fourney provide on AutoGen, and how does it handle complex tasks with multiple agents?
Microsoft research copilot experience
What updates did Adam Fourney provide on AutoGen, and how does it handle complex tasks with multiple agents?