

As large language models (LLMs) continue to improve at writing code, a key challenge has emerged: enabling them to generate complex, high-quality training data that actually reflects real-world programming.
Currently, most data synthesis methods rely on simple code snippets as starting points. While these fragments are useful for illustrating specific functions, they often fail to capture the complexity of actual software development—such as elaborate architectures, module dependencies, and cross-file logic. As a result, training data lacks the structural and semantic depth needed for models to generalize and perform well on advanced tasks.
To address this, Microsoft Research Asia has developed a feature tree–driven data synthesis framework that models the hierarchical organization of code based on its semantic features. Instead of relying on isolated fragments, the framework extracts key elements like variable types, function structures, and control flows to construct a layered “feature tree.” This tree guides the systematic generation of diverse and complex training instructions.
Using this approach, the research team developed and trained a new model called EpiCoder (opens in new tab), which is setting new benchmarks. They made the dataset (opens in new tab) and code repository (opens in new tab) publicly available.
A semantic leap in code generation
Unlike traditional approaches that use abstract syntax trees to model code structure, the feature tree framework focuses on the semantic relationships between code elements. This “feature-to-structure” approach improves the diversity and coverage of generated data, better mirroring the logic of real-world codebases.
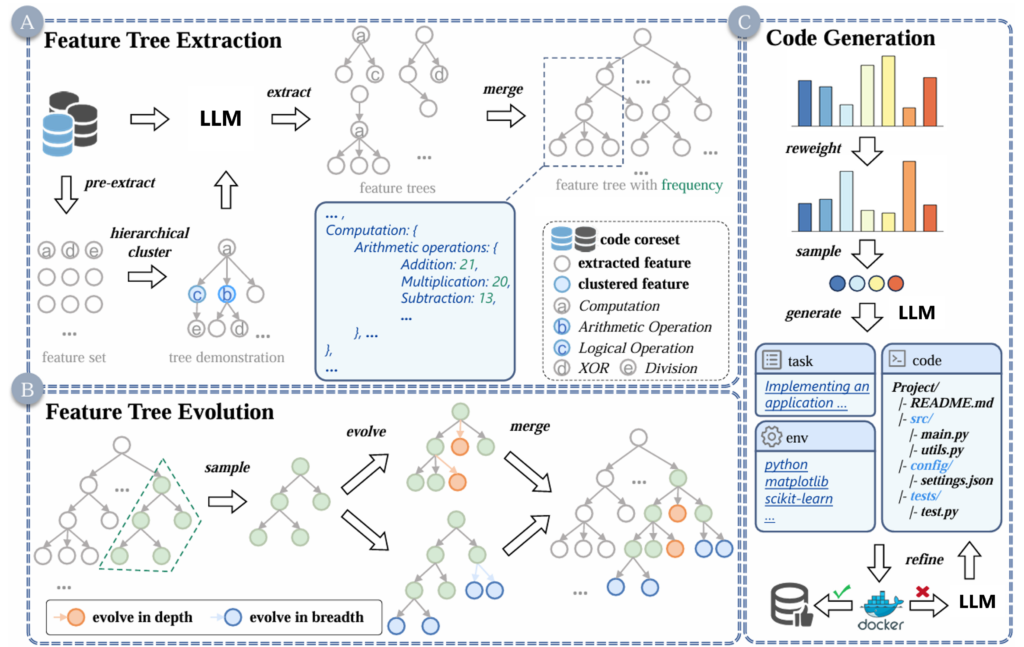
Illustrated in Figure 1, the framework operates in three core stages:
1. Feature tree extraction
Starting with an initial code dataset, researchers extract semantic features and group them through clustering to build a hierarchical tree. A tree demo was used to teach LLMs how to extract and organize these features, helping them establish relationships among code components.
2. Feature tree evolution
To expand semantic diversity, the team introduced a tree “evolution” mechanism. By adjusting the tree’s depth and breadth, they generate subtrees that represent increasingly complex code structures. This evolution reflects real development workflows—progressing from functions to modules and from modules to full files.
3. Feature tree–guided code generation
Using these subtrees, LLMs can generate targeted code samples with specific semantics, achieving on-demand synthesis. A probabilistic sampling method further improves coverage in weaker model areas, helping the model learn edge cases and rare structures.
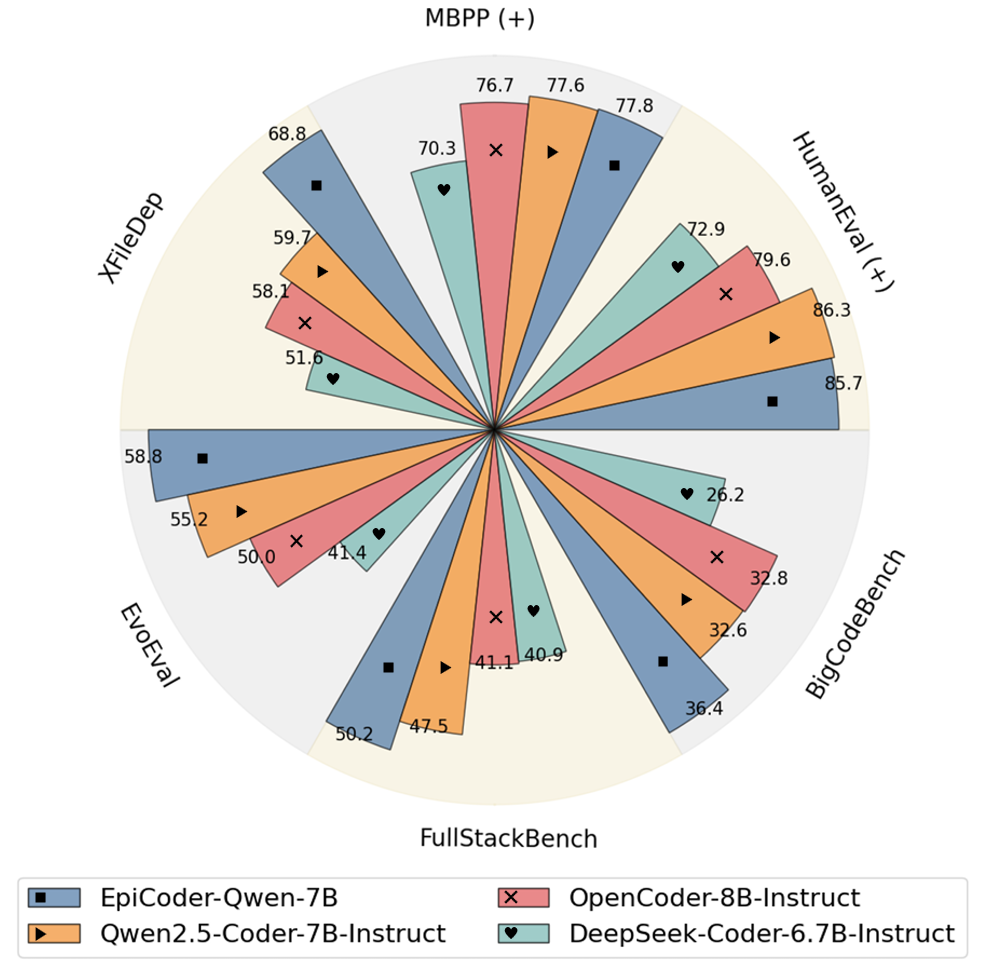
Evaluating EpiCoder across benchmarks and repository-scale tasks
Using this framework, researchers synthesized over 430,000 instruction samples covering a broad range of tasks, from individual functions to full file-level compositions. These samples were used to fine-tune two base models, Qwen2.5-Coder-7B-Base and DeepSeek-Coder-6.7B-Base, resulting in the EpiCoder model.
EpiCoder achieved state-of-the-art performance across both function- and file-level benchmarks.
The team also explored how this approach could scale to repository-level code synthesis. Using the “LLM-as-a-judge” evaluation me thod, they quantitatively assessed the complexity and diversity of the generated data. The approach produced more complex and diverse code than baseline methods, confirming its advantage in generating realistic, high-quality training data.

Toward more controllable and interpretable code intelligence
Traditional data synthesis techniques for code often lack semantic granularity and controllability. The feature tree framework addresses this by improving the structure and interpretability of synthetic data, helping lay the foundation for more transparent and systematic code LLMs.
EpiCoder’s success highlights the value of feature-driven semantic modeling as a foundation for training next-generation code models. As the framework continues to evolve, it could support a wide range of applications, including targeted knowledge completion, structured code understanding, and automated repository refactoring.



