

作者:工程与基础架构组
编者按:随着代码大模型能力的不断增强,高质量指令数据的构造成为释放其潜力的关键。然而,现有方法普遍依赖单一的代码片段作为构造种子,限制了数据的复杂度与多样性。近日,微软亚洲研究院联合厦门大学、清华大学提出全新特征树驱动的数据合成框架,通过建模代码语义层级关系,实现了对合成代码复杂度的精细控制,并支持从函数级到多文件级的多样任务生成。基于该框架训练得到的 EpiCoder 模型在多个基准测试上表现突出,展示了其在真实编程场景中处理复杂任务的强大能力,为大模型代码能力的进一步释放提供了全新范式。
随着大语言模型(LLMs)在代码生成任务中的不断进步,如何进一步挖掘模型的能力,合成或生成复杂且多样的高质量代码数据成为关键问题。然而,现有的数据合成方法普遍依赖简单的代码片段作为种子。这些片段虽然能表达特定功能,但难以涵盖复杂结构、模块间交互或跨文件逻辑等真实世界场景中常见的编程需求。因此,所合成的训练数据往往缺乏结构性和语义深度,限制了模型在更高层次任务中的泛化能力及表现。
为解决这一问题,微软亚洲研究院提出了一种全新的特征树(Feature Tree)驱动的数据合成框架。该框架从代码的“语义特征”出发,建模其层级关系,重构代码知识的组织方式。这一方法不再依赖孤立的代码片段,而是通过抽取变量类型、函数结构、控制流等语义特征,构建出语义层级清晰的特征树,从中系统性地生成具备多样性和复杂性的指令数据。基于该框架,研究员们进一步训练得到了 EpiCoder 模型。
代码链接:https://github.com/microsoft/EpiCoder (opens in new tab)
数据链接:https://huggingface.co/datasets/microsoft/EpiCoder-func-380k (opens in new tab)
论文链接:https://arxiv.org/abs/2501.04694 (opens in new tab)
代码生成进入“语义理解”新阶段
不同于传统依赖语法树(Abstract Syntax Tree, AST)建模代码结构的方法,特征树框架聚焦于代码元素之间的语义关系。它以一种“从特征到结构”的方式指导数据的合成过程,提升生成代码的多样性和覆盖度,更符合真实代码库的组织逻辑。
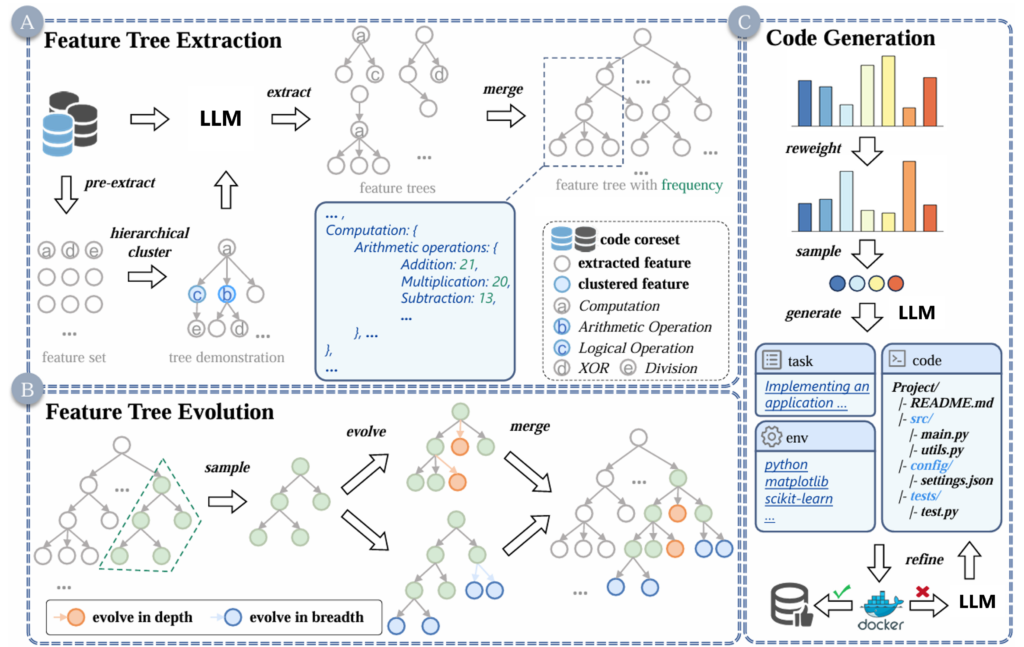
特征树框架由三个关键步骤组成:
1. 特征树抽取(Feature Tree Extraction):
通过对初始代码数据集进行特征提取和语义聚类,构建出一棵分层的特征树。研究员们首先构造了一个结构示例(tree demo)作为引导,让 LLMs 学会如何从原始代码中抽取语义特征,逐步建立代码片段之间的关联结构。
2. 特征树演化(Feature Tree Evolution):
为进一步提升特征多样性,研究员们设计了树的“演化”机制,通过控制树的深度和广度,生成语义结构逐渐复杂的子树。这种树结构能够反映现实开发中从函数到模块、从模块到文件的编程构造方式,从而实现了从简单到复杂任务的自然过渡。
3. 基于特征树的数据合成(Feature Tree-Based Code Generation):
在树结构的指导下,LLMs 可针对某一特征子树生成具备特定语义的代码实例,实现“按需生成”。不仅如此,研究员们还引入了概率采样机制,可针对模型薄弱区域有针对性地加强数据覆盖,提升模型对边缘特征的学习效果。
突破数据复杂度瓶颈,打造高质量模型基座
基于上述框架,研究员们构建了超过43万条指令数据,涵盖从函数级到文件级的广泛任务,并在 Qwen2.5-Coder-7B-Base 和 DeepSeek-Coder-6.7B-Base 两大主流基础模型上进行了微调,得到的 EpiCoder 模型在函数级和文件级测试基准上均取得 SOTA 表现。
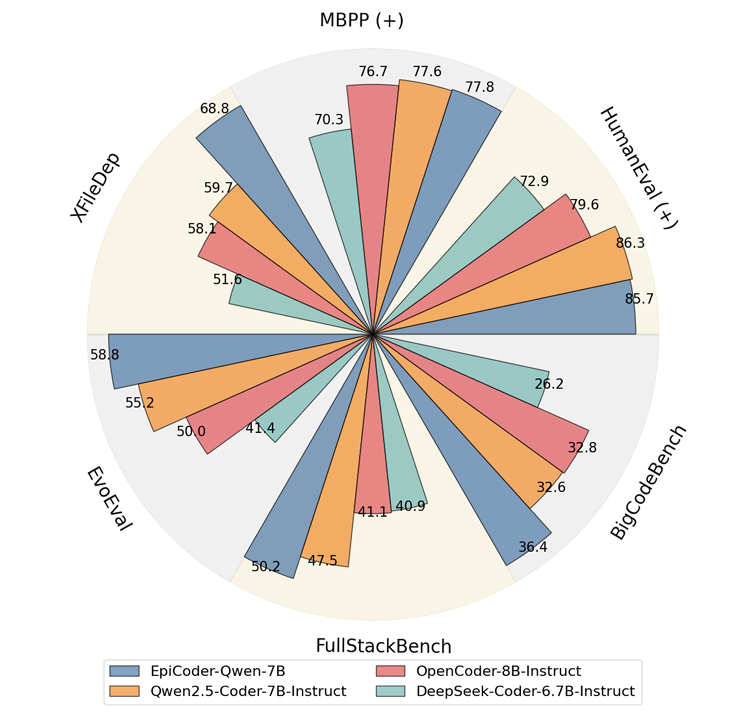

研究员们还进一步探索了该方法在“代码仓库级”合成任务中的可行性,并通过 “LLM-as-a-judge” 评估范式,从复杂度与多样性两个角度对合成数据进行量化分析,验证了特征树框架在构造真实感数据方面的显著优势。
迈向可控、可解释的代码智能
传统代码指令数据合成方法在可控性和语义深度上往往存在明显短板,而特征树方法的引入不仅带来了数据合成“粒度”的提升,也为未来构建具备可解释性与系统性的大模型打下了基础。
基于特征树框架训练得到的 EpiCoder 模型的成功表明,借助特征驱动的语义建模方式,可以为代码大模型建设更稳健、更高质量的训练基座。随着该框架的进一步拓展,其有望在定向知识补全、结构代码理解、仓库自动重构等任务中展现出更广泛的价值。



